
Privacy by Design approach
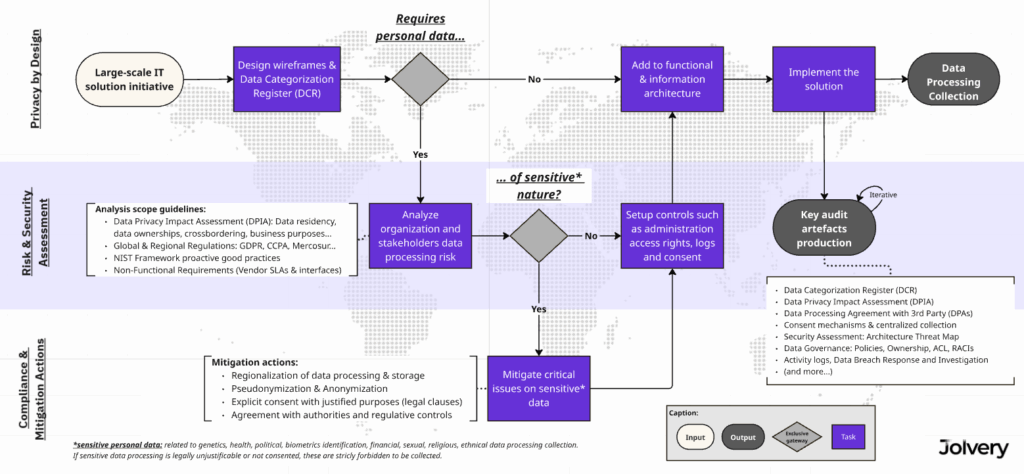
Managing data confidentiality on a large scale is based on a fundamental business need: ensuring stakeholders trust while meeting legal obligations. It is essential to address these concerns from the design phase of any IT solution handling personal data. This involves mastering cross-border data flows and limiting data collection to what is strictly necessary (wireframing and data cataloguing could help scope the data to be collected). From a business perspective, this means implementing a robust data governance accross the company as well as implementing measures such as centralizing consent collection (e.g., in many cases, installing a mobile application is interpreted as implying consent), establishing workflows to easily respond to individuals’ rights (such as access, rectification, and deletion requests).
Risk & Security assessments
Once requirements have been identified, each data processing operation must be associated with a level of risk, both for the organization who implement the large scale solution and for the end users. This analysis is based on the nature of the personal data (sensitive or not), its volume, and the purposes of the processing. The NIST[1] framework can be used to align risk levels with appropriate security measures, such as encryption, granular access control, continuous monitoring or access audits. The higher the risk, the more robust and well-documented the safeguards must be. This assessment enables proactive prioritization of cybersecurity investments based on real exposure.
Mitigation actions for regulatory compliance
Compliance with data protection regulations is essential. A DPIA (Data Protection Impact Assessment)[2] is mandatory for high-risk processing under the GDPR. It identifies potential risks to individuals’ rights and freedoms and proposes mitigating measures. In China, for example, when large-scale personal data is collected, one approach may involve localizing cloud infrastructure to avoid cross-border transfers outside the domestic legal framework (Art. 40 – PIPL)[3]. More broadly, this may require integrating security mechanisms such as anonymization or pseudonymization. Other key obligations include maintaining an up-to-date Data Categorization Register (DCR)[4] managing explicit consent, and ensuring traceability through access logs. These elements not only support compliance but also provide demonstrable evidence in the event of audit.
[1] National Institute of Standards and Technology (NIST): A framework widely recognized in the IT industry, providing best practices for cybersecurity and data protection.
https://www.nist.gov/cyberframework/informative-references
[2] Data Protection Impact Assessment (DPIA): artefact helping in defining personal data processing and limiting risks
[3] Personal Information Protection Law (PIPL):
https://personalinformationprotectionlaw.com/chapter-iii-rules-for-cross-border-provision-of-personal-information/
[4] Data Categorization Register (DCR): A structured inventory that supports data governance by analyzing data collection risks, classifying personal data types, identifying data ownership, and guiding implementation. Note that while a DCR can inform a DPIA by providing essential input (e.g., what personal data is being processed, its sensitivity, and where it is stored), the DCR is broader in scope than the DPIA and focuses on ongoing data governance, even when a DPIA is not required.