
Design-think your AI-powered Product
In a context where data and artificial intelligence fuel for faster informed decisions, it’s crucial to have an architecture capable of transforming raw data, especially here in this case semi-structured from various sources, into actionable, more structured insights, in a daily and safe fashion for your company positioning.
After design-thinking customer’s product requirements and exploring the various solutions available, we decided for this context, various semi-structured sources, on the tool Snowflake. Snowflake enables us to build what we call a “data warehouse” architecture which provides a robust, sustainable and end-to-end streaming data pipeline: from raw/semi-structured daily data updates to live stream advanced analysis and predictive models (AI, Machine Learning).
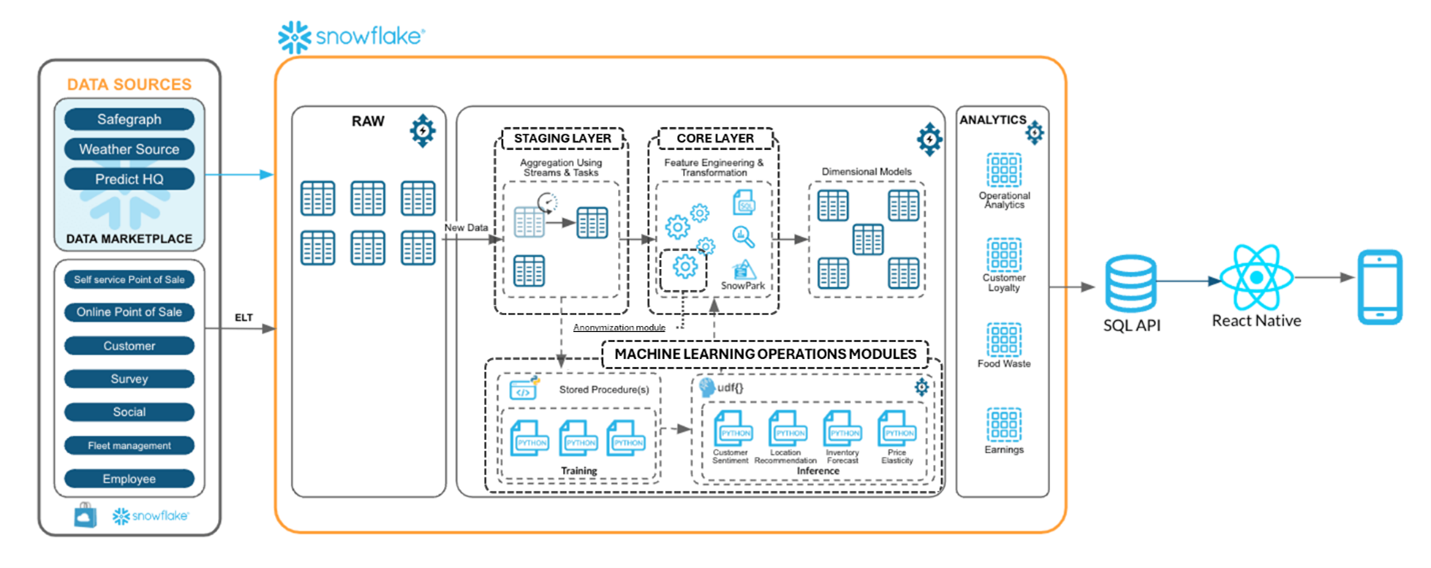
Centralizing our sources (Raw Layer)
Various data streams (structured or semi-structured), such as customer data, historical and IoT databases feed the system via efficient ELT/ETL[1] processes. Snowpipe, APIs REST and native connectors enable automated, near-real-time ingestion!
Transformation & harmonization (Core Layer)
Thanks to features such as Streams, Tasks, Snowpark, and advanced transformation functions, data are cleansed, enriched and ready for exploitation. What’s more, views (materialized or not) can be used to create a harmonized core layer ready for inference.
In this organized approach, this data warehouse architecture serves the Single Source of Truth principle by avoiding multiple duplications of data hubs in or out.
Integrated Anonymization
Handle with care as sensitive data[2] must never be compromised. Privacy protection is crucial: an anonymization module is integrated into the analytics phase to guarantee GDPR or HIPAA compliance. We recommend duplicating this module in cases of regionalization, to ensure that personal data are stored locally in compliance with regional regulations
Operational Machine Learning modules
Snowpipe enables loading data from files as soon as they’re available in a stage. This means you can load data from files in micro-batches, making it available to users within minutes, rather than manually executing COPY statements on a schedule to load larger batches.
Thanks to stored procedures and UDF functions, we can integrate ML training and model inference modules directly into Snowflake – no need to export data or create system, process APIs, connectors for AI. [3] And as a result, the data warehouse is an accelerator for generative AI or any other digital innovative product, analytics. More on this topic in our Webinar (see below)
Insights available to all (Data Consumers)
Business and end users can consume these insights via SQL APIs or via mobile apps developed in React Native[4], for fast, portable decision-making. Use SQL API to connect to the Snowflake data-bases from the mobile phone app (in our context it was a .NET[5] environment).
Take Away:
- Design-think product requirements and the metrics for your business, the digital or AI product
- Power AI at scale without sacrificing data privacy, using the strength of a modern data warehouse
- Perform a cost analysis and a proof-of-concept to validate medium/long-term product/business hypotheses
Subscribe and Learn More with our next Free Webinar: